一、什么是一致性hash
普通的hash算法 (hashcode % size ),如果size发生变化,几乎所有的历史数据都需要重hash、移动,代价非常大,常见的java中的hashmap就是如此。
那如果在hash表扩容或者收缩的时候size能够保持不变,即历史数据在hash表中的位置不变,这样就解决了hash表阔缩时的大量数据移动问题。
一致性hash可以理解,就是hash函数(hashcode%size)的size保持不变,从而保证了hash函数的前后一致性。
二、一致性hash算法介绍
一致性hash算法主要应用在分布式缓存系统中,在增加或者删除服务器节点时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系,也就是系统中的大多数历史缓存的存储服务器节点可以不变,解决了普通hash算法带来的动态伸缩性问题。

如上图一致性hash定义了一个 0 ~ 2^32-1 hash环,hash函数并不是按照服务器节点的数量取模,而是按照 2^32 取模(hashcode % 2^32),这样请求的数据就会落在环上某个固定的位置。
服务器节点按照IP或域名进行hash,分配到hash环上,如图分配了4个服务器节点,分别在hash环的 10000、20000、30000、40000 位置(为了方便演示)。

插入数据
请求数据先通过hash函数(hashcode % 2^32)确定了在环上的位置,再沿着环顺时针查找,遇到的第一个节点就是命中的服务器节点。

新增、删除节点
新增节点E (25000),按照一致性hash算法,只有B ~ E 之间的历史数据会受到影响,(之前是路由到C的,现在路由到 E ),即只有C的一部分数据需要迁移到E。
删除节点B,那么 A~ B 之间的历史数据丢失,并且新增数据会被插入到 C,其他的节点都不会受到影响。
可以看到一致性hash算法,节点的增删都只会影响了系统中的一小部分数据,容错性非常好。
但是上面的模型还是有个问题,如果服务器节点太少或者出现热点数据,就会导致服务器节点上之间的数据分布不均匀;并且还可能出现缓存雪崩的问题。
如果每个服务器在环上只有一个节点,那么当服务器宕机,它原本所负责的缓存数据将全部交由顺时针方向的下一个服务器节点处理。例如,当 B 退出时,它原本所负责的缓存将全部交给 C 处理。这就意味着 C 的访问压力会瞬间增大。设想一下,如果 C 因为压力过大而崩溃,那么更大的压力又会向 D 压过去,最终服务压力就像滚雪球一样越滚越大,最终导致缓存雪崩
缓存雪崩:虚拟节点处理
一致性hash 通过引入虚拟节点解决了这个问题,每个实际节点映射多个虚拟节点,数据按照规则找到虚拟节点后,再储存到映射的实际节点上;因为虚拟节点可以在hash环上均匀分布,这意味着当一个真实节点失效退出后,它原来所承载的压力将会均匀地分散到其他节点上去,解决缓存雪崩问题

虚拟节点
三、Redis Cluster的一致性hash算法
redis cluster没有采用基于hash环的一致性算法,而是引入了哈希槽 ( slots ) 的概念,所有的数据都是存在slot中,redis cluster 一共有 2^14(16384)个slot,每个master节点负责一部分slot。

3.1 节点路由
当客户端连接向某个 master 节点发送请求时,接收到命令的节点首先会通过 CRC-16(key)%16384 计算出当前key所属的slot,如果该slot由自己负责,直接处理响应客户端的请求,如果不是,则向客户端返回MOVED重定向请求,并将该slot对应的服务器节点的ip和port一并返回,客户端拿着这些数据重新访问。
3.2 集群扩容
集群新增 master 节点后,需要通过reshard来将slot重新分配,假设我们需要向集群中加入一个D节点,而此时集群内已经有A、B、C三个节点了。此时redis-trib会向A、B、C三个节点发送迁移出slot的请求,同时向D节点发送准备导入slot的请求,做好准备之后A、B、C这三个源节点就开始执行迁移,将对应的slot所对应的键值对迁移至目标节点D。
3.3 节点宕机
针对A节点,某一个节点认为A宕机了,那么此时是主观宕机。而如果集群内超过半数的节点认为A挂了, 那么此时A就会被标记为客观宕机。
一旦节点A被标记为了客观宕机,集群就会开始执行故障转移。其余正常运行的 master 节点会进行投票选举,从A节点的 slave 节点中选举出一个,将其切换成新的master对外提供服务。当某个slave获得了超过半数的master节点投票,就会成功当选,成功之后停止复制A节点,使自己成为master。然后将A节点所负责处理的slot,全部转移给自己,然后就会向集群发PONG消息来广播自己的最新状态。
可以看到对于Redis Cluster,CRC-16(key)%16384 保证了某个key只会落固定的一个slot上,并不需要关心它最终要去到哪个服务器节点。
四、分库分表中一致性hash实践
1.基于hash环一致性hash算法的分库分表
一个简单的没有虚拟节点的一致性hash算法
public class ConsistentHashAlgorithm {
private SortedMap<Long, String> virtualNodes = new TreeMap<>();
public ConsistentHashAlgorithm(Collection<String> tableNodes) {
initNodesToHashLoop(tableNodes);
}
public void initNodesToHashLoop(Collection<String> tableNodes) {
SortedMap<Long, String> virtualTableNodes = new TreeMap<>();
for (String node : tableNodes) {
long hash = getHash(node);
virtualTableNodes.put(hash, node);
}
for (Map.Entry<Long, String> entry : virtualTableNodes.entrySet()) {
log.info("节点[" + entry.getValue() + "]被添加, hash值为" + entry.getKey());
}
this.virtualNodes = virtualTableNodes;
}
public String getTableNode(String key) {
SortedMap<Long, String> subMap = virtualNodes.tailMap(getHash(key));
if (subMap.isEmpty()) {
return virtualNodes.get(virtualNodes.firstKey());
}
return subMap.get(subMap.firstKey());
}
/**
* 使用FNV1_32_HASH算法计算key的Hash值
*
* @param key
* @return
*/
public long getHash(String key) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0) {
hash = Math.abs(hash);
}
return hash;
}
}sharding-jdbc 自定义分片策略
public class ConsistentShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
private ConsistentHashAlgorithm consistentHashAlgorithm;
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
if (consistentHashAlgorithm == null) {
consistentHashAlgorithm = new ConsistentHashAlgorithm(collection);
}
return consistentHashAlgorithm.getTableNode(String.valueOf(preciseShardingValue.getValue()));
}
}sharding-jdbc 配置
# 一致性hash 分表测试
pick_task:
actual-data-nodes: ds0.pick_task_$->{0..4}
tableStrategy:
standard:
shardingColumn: place_id
precise-algorithm-class-name: com.simplezero.coding.sharding.repository.sharding.ConsistentShardingAlgorithm可以看到:
节点[pick_task_1]被添加, hash值为1045769218
节点[pick_task_3]被添加, hash值为1077989284
节点[pick_task_0]被添加, hash值为1225972537
节点[pick_task_2]被添加, hash值为1999305687如果增加节点 pick_task_4,此时根据 一致性hash算法,只有 pick_task_2 表数据需要迁移
节点[pick_task_1]被添加, hash值为1045769218
节点[pick_task_3]被添加, hash值为1077989284
节点[pick_task_0]被添加, hash值为1225972537
节点[pick_task_4]被添加, hash值为1959358845
节点[pick_task_2]被添加, hash值为19993056872.美团的一致性hash方案
直接分32库32表,通过userId后四位 % 32 分库 userId后四位 / 32 %32 分表,共计分为1024张表。线上部署情况为8个集群(主从),每个集群4个库。
场景一:数据库性能达到瓶颈

将逻辑数据库升级到 --> 物理数据库--> 数据库集群 ,分库分表规则不变,最多可以直接扩展到32个数据库集群

如果32个集群也无法满足需求,那么将分库分表规则调整为(32*2^n)*(32/2^n),可以达到最多1024个集群,即每张表一个集群。
场景二:单表容量达到瓶颈(或者1024已经无法满足你)

如果1024张表都不能满足你了,这时,可以保持分库规则不变,单库里的表再进行裂变
tb_(userId后四位 div 32 mod 32)_(userId后四位 div 32 mod 32 mod 8) ==> db_4.tb_3_7userId后四位 div 32 mod 32在目前订单这种规则下(用userId后四位 mod)还是有极限的,因为只有四位,所以最多拆8192个表。
不过这个时候就不能一劳永逸,需要进行库内的表数据迁移了。
3.平均分布方案
直接32库32表1024张表,固然可以一步到位,但是对于小公司来说前期根本用不上,浪费机器且增加系统复杂度,所以还是循序渐进,按照一致性hash算法的思想,先确定总的节点数为32
32 = 节点count * 数据库数量
database_index = key % 32 / count * count
//分2库 count = 32 / 2 = 16
database_index = key % 32 / 16 * 16 ==> db_0(0-15) db_16(16-31)
//分4库 count = 32 / 4 = 8
database_index = key % 32 / 8 * 8 ==> db_0(0-7) db_8(8-15) db_16(16-23) db_24(24-31)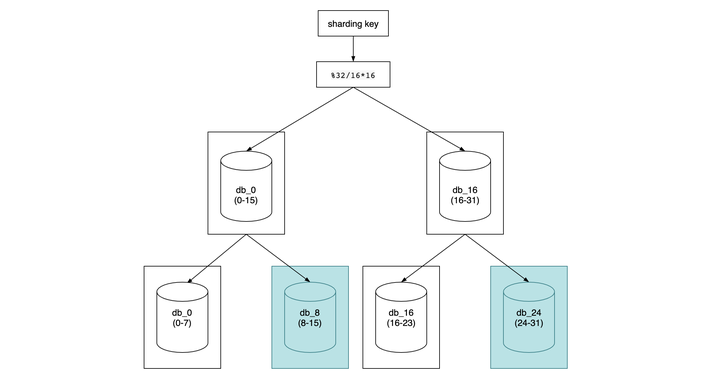
可以看到如果从2库扩展到4库,需要从 db_0 移动一半的数据到 db_8,db_16 也同样要移动。
db_0(0-15)==> db_0(0-7)+ db_8(8-15)可以看到当需要进行扩容一倍时需要迁移一半的数据量,如果量比较大,影响还是比较大。
这个方案还可以进行优化,一致性hash的算法不变,每次增加1个节点,而不是每次增加2^n个节点,这样可以尽量平滑的进行扩容。
//分2库 count = 32 / 2 = 16
database_index = key % 32 / 16 * 16 ==> db_0 db_16
//分3库 count = 32 / 4 = 8
database_index = key % 32 / 8 * 8 ==> db_0(0-7) db_8(8-15) db_16(16-31)此时就需要改分片路由的规则了
Integer dbValue = userId % 32 / 8 * 8 ;
if(dbValue >= 16){
return 16;
} else {
return dbValue;
}
借鉴:一致性hash